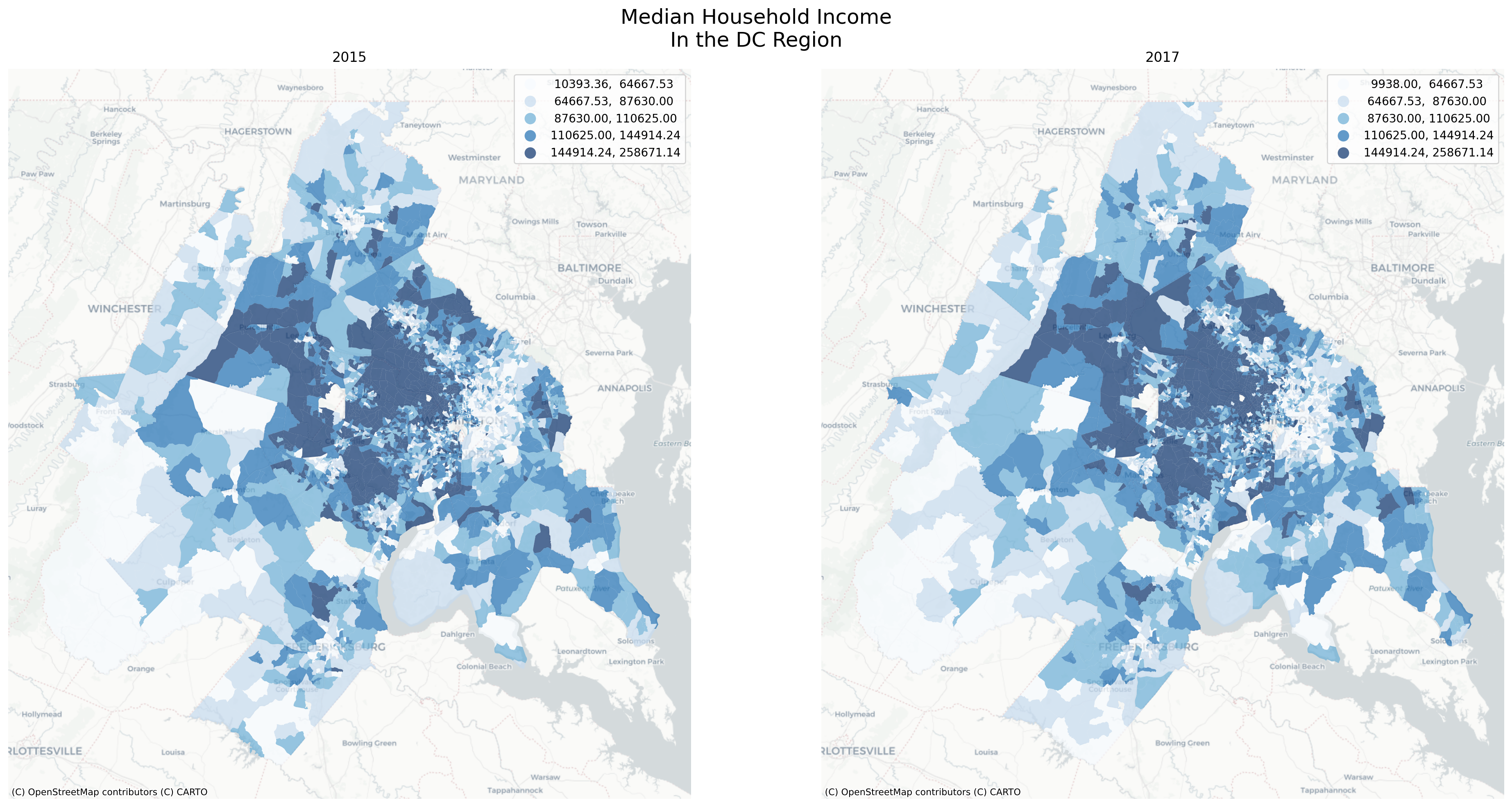
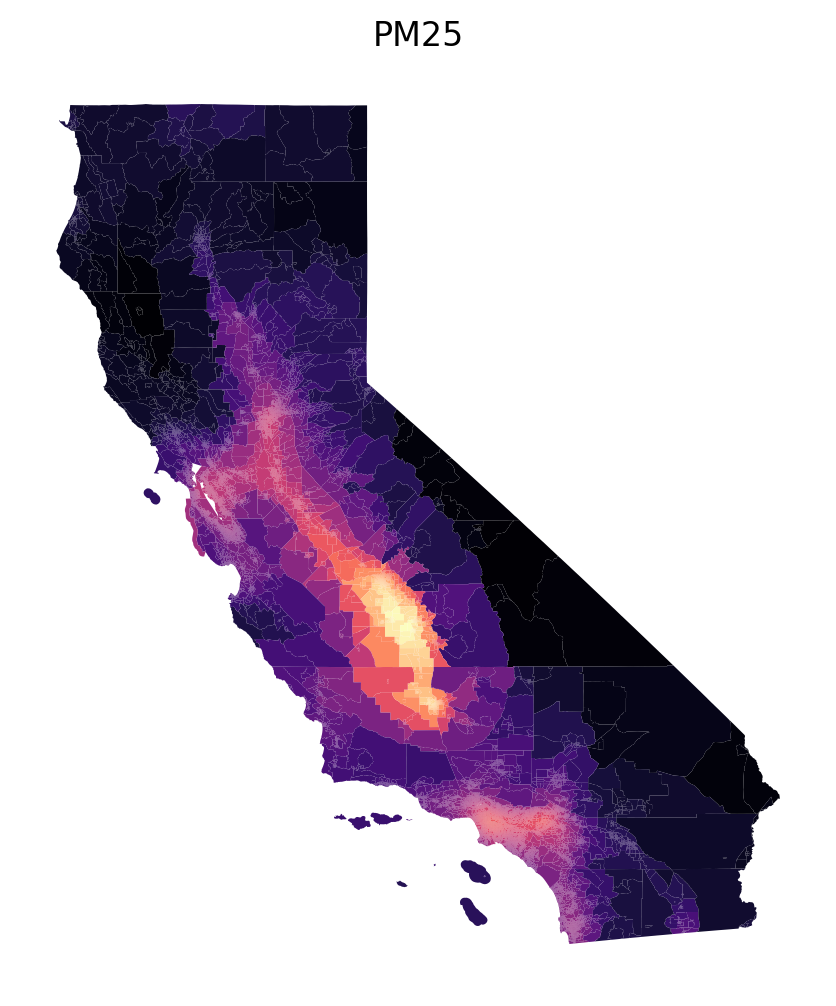
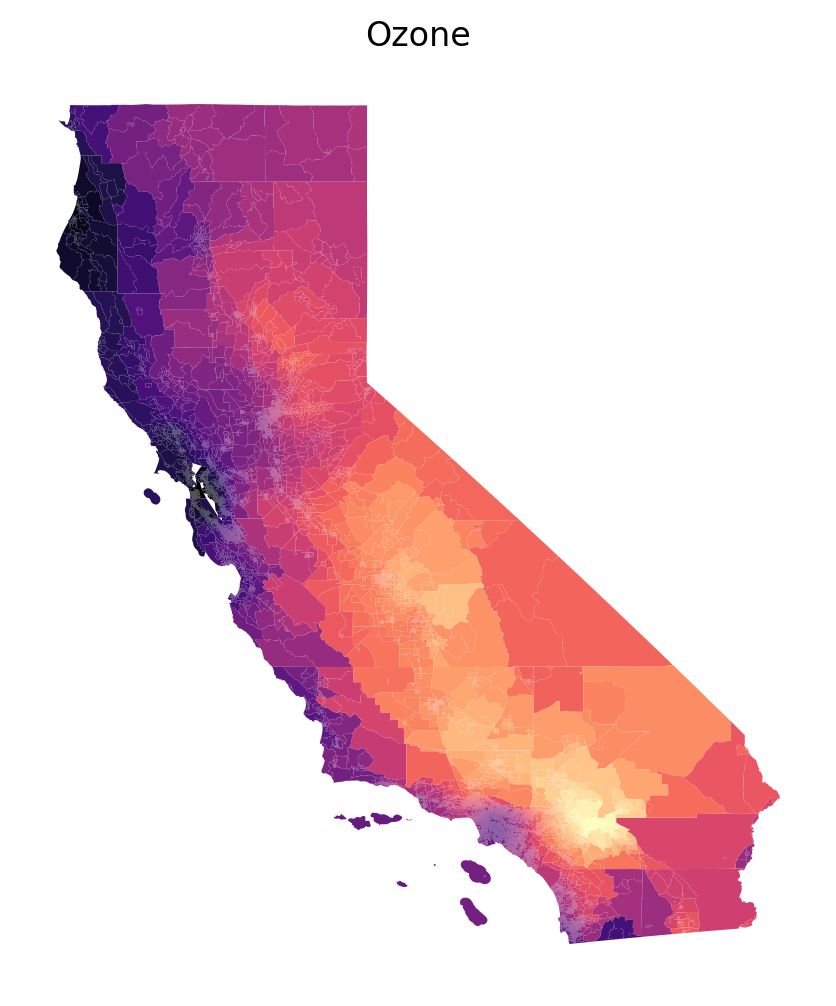
Code
from geosnap import io as gio
from geosnap import visualize as gvz
from geosnap import DataStore
import geopandas as gpd
import matplotlib.pyplot as plt
%load_ext jupyter_black
%load_ext watermark
%watermark -a 'eli knaap' -ivAuthor: eli knaap
geosnap : 0.12.1.dev9+g3a1cb0f6de61.d20231212
geopandas: 0.14.1