Code
import contextily as ctx
import geopandas as gpd
import matplotlib.pyplot as plt
from geosnap import DataStore
from geosnap import analyze as gaz
from geosnap import io as gio
from geosnap import visualize as gvzimport contextily as ctx
import geopandas as gpd
import matplotlib.pyplot as plt
from geosnap import DataStore
from geosnap import analyze as gaz
from geosnap import io as gio
from geosnap import visualize as gvz%load_ext watermark
%watermark -a 'eli knaap' -iv -d -uAuthor: eli knaap
Last updated: 2024-01-21
contextily: 1.4.0
geopandas : 0.14.2
matplotlib: 3.8.2
geosnap : 0.12.1.dev9+g3a1cb0f6de61.d20240110
Geodemographic analysis, which includes the application of unsupervised learning algorithms to demographic and socioeconomic data, is a widely-used technique that falls under the broad umbrella of “spatial data science”. Technically there is no formal spatial analysis in traditional geodemographics, however given its emphasis on geographic units of analysis (and subsequent mapping of the results) it is often viewed as a first (if not requisite step) in exploratory analyses of a particular study area.
The intellectual roots of geodemographics extend from analytical sociology and classic studies from Factorial Ecology and Social Area Analysis. Today, demogemographic analysis is routinely applied in academic studies of neighborhood segregation and neighborhood change, and used extremely frequently in industry, particularly marketing where products like tapestry and mosaic are sold for their predictive power. Whereas social scientists often look at the resulting map of neighborhood types and ask how these patterns came to be, practitioners often look at the map and ask how they can use the patterns to inform better strategic decisions.
In urban social science, our goal is often to undertand the social composition of neighborhoods in a region, understand whether they have changed over time (and where) and whether these neighborhood types are consistent over time and across places. That requires a common pipeline of collecting the same variable sets, standardizing them (often within the same time period so they can be pooled with other time periods) then clustering the entire long-form dataset followed by further analysis and visualization of the results. Most often, this process happens repeatedly using diffferent combinations of variables or different algorithms or cluster outputs (and in different places at different times). Geosnap provides a set of tools to simplify this pipeline
datasets = DataStore()atl = gio.get_acs(datasets, msa_fips="12060", years=2021, level="tract")/Users/knaaptime/Dropbox/projects/geosnap/geosnap/io/util.py:275: UserWarning: Unable to find local adjustment year for 2021. Attempting from online data
warn(
/Users/knaaptime/Dropbox/projects/geosnap/geosnap/io/constructors.py:215: UserWarning: Currency columns unavailable at this resolution; not adjusting for inflation
warn(atl[["median_household_income", "geometry"]].explore(
"median_household_income",
scheme="quantiles",
k=8,
cmap="magma",
tiles="CartoDB Positron",
)atl.columnsIndex(['geoid', 'n_mexican_pop', 'n_cuban_pop', 'n_puerto_rican_pop',
'n_russian_pop', 'n_italian_pop', 'n_german_pop', 'n_irish_pop',
'n_scandaniavian_pop', 'n_foreign_born_pop',
...
'p_poverty_rate', 'p_poverty_rate_over_65', 'p_poverty_rate_children',
'p_poverty_rate_white', 'p_poverty_rate_black',
'p_poverty_rate_hispanic', 'p_poverty_rate_native',
'p_poverty_rate_asian', 'geometry', 'year'],
dtype='object', length=158)columns = [
"median_household_income",
"median_home_value",
"p_edu_college_greater",
"p_edu_hs_less",
"p_nonhisp_white_persons",
"p_nonhisp_black_persons",
"p_hispanic_persons",
"p_asian_persons",
]atl[columns]| median_household_income | median_home_value | p_edu_college_greater | p_edu_hs_less | p_nonhisp_white_persons | p_nonhisp_black_persons | p_hispanic_persons | p_asian_persons | |
|---|---|---|---|---|---|---|---|---|
| 0 | 100046.0 | 269800.0 | 36.410007 | 7.772650 | 66.726619 | 13.979725 | 8.371485 | 7.406802 |
| 1 | 68911.0 | 161700.0 | 13.808050 | 17.275542 | 66.060862 | 6.170752 | 22.104818 | 2.831784 |
| 2 | 78712.0 | 202100.0 | 14.972459 | 16.374562 | 70.527071 | 1.470061 | 18.465400 | 7.995697 |
| 3 | 53072.0 | 162000.0 | 9.760178 | 17.735639 | 64.627151 | 8.604207 | 19.005736 | 3.288719 |
| 4 | 64917.0 | 159100.0 | 23.516484 | 14.212454 | 70.119425 | 1.852303 | 12.576164 | 14.184743 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1495 | 61926.0 | 178700.0 | 14.130691 | 11.040340 | 85.844513 | 5.177159 | 4.179567 | 2.149983 |
| 1496 | 65139.0 | 230800.0 | 29.907407 | 7.731481 | 72.192354 | 18.906810 | 4.121864 | 4.510155 |
| 1497 | 53805.0 | 190100.0 | 12.632922 | 28.966397 | 54.473684 | 28.479532 | 9.269006 | 0.672515 |
| 1498 | 80037.0 | 215100.0 | 24.821630 | 18.700713 | 71.843402 | 20.948924 | 6.844698 | 0.000000 |
| 1499 | 78380.0 | 258300.0 | 14.397394 | 29.934853 | 72.871236 | 26.739356 | 0.389408 | 0.000000 |
1500 rows × 8 columns
To create a simple geodemographic typology, use the cluster function and pass a geodataframe, a set of columns to include in the cluster analysis, the algorithm to use and the number of clusters to fit (though some algorithms require different arguments and/or discover the number of clusters endogenously. By default, this will z-standardize all the input columns, drop observations with missing values for input columns, realign the geometries for the input data, and return a geodataframe with the cluster labels as a new column (named after the clustering algorithm)
atl_kmeans, atl_k_model = gaz.cluster(
gdf=atl, method="kmeans", n_clusters=5, columns=columns, return_model=True
)/Users/knaaptime/mambaforge/envs/geosnap/lib/python3.11/site-packages/sklearn/cluster/_kmeans.py:1420: FutureWarning: algorithm='auto' is deprecated, it will be removed in 1.3. Using 'lloyd' instead.
warnings.warn(atl_kmeans[columns + ["geometry", "kmeans"]].explore(
"kmeans", categorical=True, cmap="Accent", tiles="CartoDB Positron"
)There are two obvious patterns in this map. There’s an urban-rural distinction, where type 1 dominates the periphery of the metro, and is basically absent from the core. There is also a north-south distinction, where type 0 is exclusively located in the southern portion and type 3 is exclusively in the north. Types 2 and 4 seem to have their own distinctive pockets. Even at this surface level, the map tells a pretty powerful story about multivariate segregation in the region. The kmeans clustering algorithm does not consider space at all, yet all of the types form distinctive spatial clusters that are apparent in the map. We can also conduct formal tests for whether these patterns diverge from spatial randomness using join count statistics either individually for each cluster or jointly for all clusters (though it is pretty obvious here that a co-location statistic for these five variables would be wildly significant)
To understand what the clusters are identifying, another data visualisation technique is useful. Here, we rely on the Tufte-ian principle of “small multiples”, and create a set of violin plots that show how each variable is distributed across each of the clusters. Each of the inset boxes shows a different variable, with cluster assignments on the x-axis, and the variable itself on the y-axis The boxplot in the center shows the median and IQR, and the “body” of the “violin” is a kernel-density estimate reflected across the x-axis. In short, the fat parts of the violin show where the bulk of the observations are located, and the skinny “necks” show the long tails.
gvz.plot_violins_by_cluster(atl_kmeans, columns, cluster_col="kmeans")array([<Axes: title={'center': 'median_household_income'}, xlabel='kmeans', ylabel='median_household_income'>,
<Axes: title={'center': 'median_home_value'}, xlabel='kmeans', ylabel='median_home_value'>,
<Axes: title={'center': 'p_edu_college_greater'}, xlabel='kmeans', ylabel='p_edu_college_greater'>,
<Axes: title={'center': 'p_edu_hs_less'}, xlabel='kmeans', ylabel='p_edu_hs_less'>,
<Axes: title={'center': 'p_nonhisp_white_persons'}, xlabel='kmeans', ylabel='p_nonhisp_white_persons'>,
<Axes: title={'center': 'p_nonhisp_black_persons'}, xlabel='kmeans', ylabel='p_nonhisp_black_persons'>,
<Axes: title={'center': 'p_hispanic_persons'}, xlabel='kmeans', ylabel='p_hispanic_persons'>,
<Axes: title={'center': 'p_asian_persons'}, xlabel='kmeans', ylabel='p_asian_persons'>,
<Axes: >], dtype=object)
Note that in this case we are visualizing the same attributes used to create the cluster model because this is what differentiates the clusters from one another, but the columns argument accepts a list of any variables present in the dataframe. This can be useful for examining the distribution of another variable across the clusters. For example if the clusters are based purely on sociodemographic data and an analyst wants to treat cluster assignments as “exogenous” and examine how another resource like affordable housing or exposure to pollution is spread across the different neighborhood types
We can also use a statistic to tell us how well this model fits the data. To do so, we can use scikit-learn’s silhouette score
The Silhouette Coefficient is calculated using the mean intra-cluster distance (a) and the mean nearest-cluster distance (b) for each >sample. The Silhouette Coefficient for a sample is (b - a) / max(a, b). To clarify, b is the distance between a sample and the nearest >cluster that the sample is not a part of. Note that Silhouette Coefficient is only defined if number of labels is 2 <= n_labels <= >n_samples - 1.
This function returns the mean Silhouette Coefficient over all samples. To obtain the values for each sample, use silhouette_samples.
The best value is 1 and the worst value is -1. Values near 0 indicate overlapping clusters. Negative values generally indicate that a sample has been assigned to the wrong cluster, as a different cluster is more similar.
The geosnap ModelResults class that is returned with the geodataframe includes a set of methods for quickly computing and visualizing these fit statistics (and their distribution in space)
atl_k_model.plot_silhouette()<Axes: title={'center': 'Silhouette Score'}, xlabel='Silhouette coefficient values', ylabel='Cluster label'>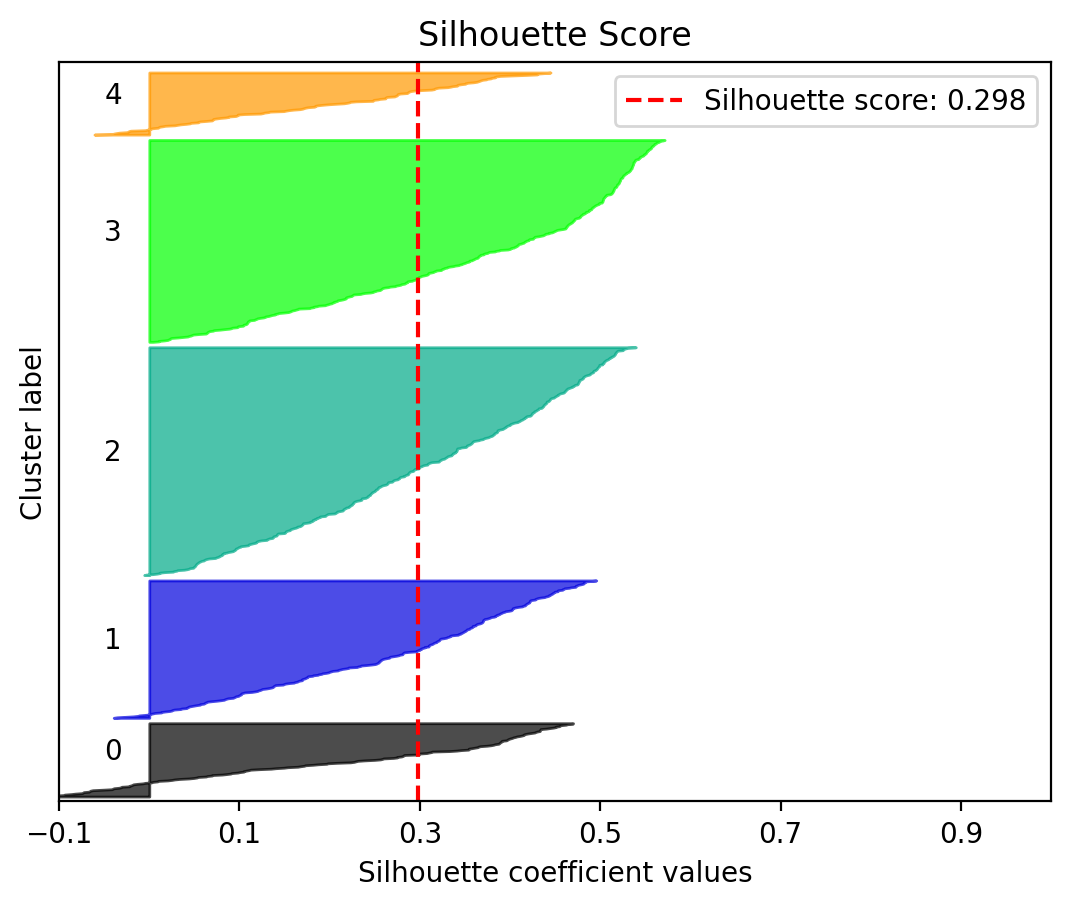
atl_k_model.plot_silhouette_map(figsize=(9, 9))/Users/knaaptime/Dropbox/projects/geosnap/geosnap/visualize/mapping.py:170: UserWarning: `proplot` is not installed. Falling back to matplotlib
warn("`proplot` is not installed. Falling back to matplotlib")[<Axes: title={'center': '2021'}>]
If there is spatial patterning in the silhouette scores for each observation, then it suggests there are particular places where the cluster model does not fit well. That could mean that a different model may work better, e.g. by increasing (or decreasing) the number of clusters, or by using a different clustering algorithm. There are many algorithms to choose from, and they differ in their ability to capture different kinds of structure in the set of attributes. For more details, see the scikit-learn clustering page, including this excellent graphic:

cluster_types = [
"kmeans",
"ward",
"affinity_propagation",
"gaussian_mixture",
"spectral",
]f, ax = plt.subplots(2, 3, figsize=(15, 10))
ax = ax.flatten()
clusters = {}
for i, k in enumerate(cluster_types):
df, mod = gaz.cluster(
gdf=atl, method=k, columns=columns, n_clusters=6, return_model=True
)
clusters[k] = (df, mod)
df.to_crs(3857).sort_values(k).plot(k, categorical=True, figsize=(7, 7), ax=ax[i])
ax[i].axis("off")
ax[i].set_title(k + f" ({mod.silhouette_score.round(3)})", fontsize=14)
ctx.add_basemap(ax=ax[i], source=ctx.providers.CartoDB.Positron)
plt.tight_layout()/Users/knaaptime/mambaforge/envs/geosnap/lib/python3.11/site-packages/sklearn/cluster/_kmeans.py:1420: FutureWarning: algorithm='auto' is deprecated, it will be removed in 1.3. Using 'lloyd' instead.
warnings.warn(
/Users/knaaptime/Dropbox/projects/geosnap/geosnap/analyze/_cluster_wrappers.py:272: UserWarning: Note: Gaussian Mixture Clustering is probabilistic--cluster labels may be different for different runs. If you need consistency, you should set the `random_state` parameter
warn(
Note that the colors do not mean anything when comparing across maps, only the patterns matter. Thus, even though the kmeans, ward, and affinity propagation maps use different colors, the algorithms are largely capturing similar patterns, as the tracts tend to end up in similar groups across the maps. According to the silhouette score, the kmeans solution fits the best (.284). Needless to say, these clusting algorithms pick up on different spatial patterns, but the most appropriate algorithm is a choice determined by the research question (or an analyst’s preferred fit metric)
To compare solutions directly, you can use holoviews to create a linked plot that will pan together (this requires hvplot and geoviews, which are not dependencies)
import geoviews as gv
import hvplot.pandas
import matplotlib.pyplot as plt
import seaborn as sns
gv.extension("matplotlib", "bokeh")
gv.output(backend="bokeh")Using a linked interactive plot we can explor similarity in the kmeans and affinity propagation solutions, which have the highes silhouette scores. This is useful to see whether they discover the same spatial patterns, but in this case also because affinity propagation is an algorithm where k is endogenous (so the affinity propagation solution here only includes 4 clusters vs the k-means’ 6).
clusters["kmeans"][0].dropna(subset=["kmeans"]).hvplot(
c="kmeans",
cmap="tab10",
line_width=0.1,
alpha=0.7,
geo=True,
tiles="CartoLight",
xaxis=False,
yaxis=False,
frame_height=450,
colorbar=False,
title='K-Means'
) + clusters["affinity_propagation"][0].dropna(subset=["affinity_propagation"]).hvplot(
c="affinity_propagation",
cmap="tab10",
line_width=0.1,
alpha=0.7,
geo=True,
tiles="CartoLight",
xaxis=False,
yaxis=False,
frame_height=450,
colorbar=False,
title='Affinity Propagation'
)